编辑 | 漠影
大模型正引发一波新的AI算力荒,从此前的芯片紧缺,上升为AI算力集群级的饥渴症。
根据产业链消息,参数可能仅30亿的Sora用4200-10500块H100训练了1个月;最新出炉的Llama 3 8B和70B的训练需要24000多块H100组成的集群;据称有1.8万亿参数的GPT-4是在10000-25000张A100上完成了训练……
OpenAI、Meta等都在用数千卡、甚至万卡串联,满足不断攀升的大模型训练需求,也给了我国大模型企业一本可参考的算力账。
然而,多位GPU算力集群业内人士告诉智东西,当下我国智能算力处于严重的供不应求状态。在GPU全球稀缺背景下,单卡性能已相对没那么重要,通过集群互联实现整体算力的最大化,成为解决AI算力荒的必要路径。
政策也已经紧锣密鼓地下发。4月24日,北京市经济和信息化局、北京市通信管理局印发《北京市算力基础设施建设实施方案(2024—2027年)》,方案提出,规划建设支撑万亿级参数大模型训练需求的超大规模智算集群,并对采购自主可控GPU芯片开展智能算力服务的企业予以支持。
产业这边的动作也没有落后。国内的头部算力厂商都已加速布局大规模智算集群,比如云服务巨头华为云打造了贵安、乌兰察布、芜湖3大AI云算力中心,头部AI芯片公司摩尔线程过去四个月也已在南京、北京亦庄和北京密云完成3座全国产千卡智算中心的落地,助国产大模型产业发展提速。
大模型产业发展对智算中心提出什么新要求?国内大规模智算中心建设的真实情况如何?如何让拔地而起的千卡甚至万卡集群实现从“建起来”到“用起来”的跨越?本文试图从摩尔线程等公司的实践,对这些问题进行探讨。
一、从Sora到Llama 3,千卡集群成百模大战标配
自2024年Sora、Claude 3、Llama 3等爆火模型推出以来,大模型的智能涌现态势不减反增,推动国内大模型厂家加速追赶,对AI算力的需求也持续升级。
国产大模型玩家无论是要持续攀登Scaling Law(规模定律)高峰,还是走行业大模型的捷径,都迫切需要更大规模算力;同时大模型向多模态方向发展,需要处理包括文本、图像、声音等多种类型的数据,亟需全功能的GPU;而行业大模型甚至需要算力厂商充当起“全栈式生态服务平台”角色,服务大模型落地的“最后一公里”。
在这些多样化新需求驱动下,将芯片系统组合起来的新型千卡智算中心,成为满足大模型产业落地的重要抓手,也成为大国AI较量的标配新基建。
产业先锋已经纷纷展开行动,国内头部AI芯片公司摩尔线程在过去四个月里加速布局了三座千卡算力集群,通过自家夸娥(KUAE)智算中心解决方案为大模型打造智算底座,开箱即用,助大模型企业解决大规模GPU算力的建设和运营管理问题。
基于夸娥打造的智算中心已经初见落地成效。目前,摩尔线程支持包括Llama、GLM、Aquila、Baichuan、GPT、Bloom、玉言等各类主流大模型的训练和微调。基于摩尔线程夸娥千卡集群,70B到130B参数的大模型训练,线性加速比均可达到91%,算力利用率基本保持不变。
以2000亿训练数据量为例,智源研究院700亿参数Aquila2可在33天完成训练;1300亿参数规模的模型可在56天完成训练。此外,摩尔线程夸娥千卡集群支持长时间连续稳定运行,支持断点续训,异步Checkpoint少于2分钟。
从传统的“重硬轻软”走向“软硬一体化”,成为这批新智算集群的普遍特点。摩尔线程夸娥就是一个软硬一体化的全栈解决方案,包括基础设施、集群管理平台及模型服务,据称可全方位降低传统算力建设、应用开发和运维运营平台搭建的时间成本。
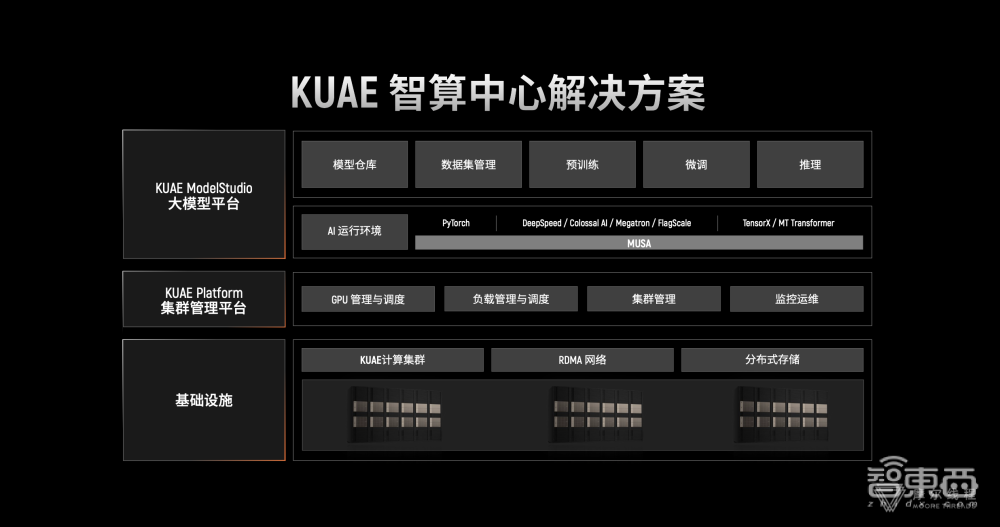
▲夸娥(KUAE)智算中心解决方案架构
基础设施:包含夸娥计算集群、RDMA网络与分布式存储。摩尔线程夸娥千卡模型训练平台,建设周期只需30天,支持千亿参数模型的预训练、微调和推理,可实现高达91%的千卡集群性能扩展系数。基于MTT S4000和双路8卡GPU服务器MCCX D800,摩尔线程夸娥集群支持从单机多卡到多机多卡,从单卡到千卡集群的无缝扩展,未来将推出更大规模的集群,以满足更大规模的大模型训练需求。
KUAE Platform集群管理平台:用于AI大模型训练、分布式图形渲染、流媒体处理和科学计算的软硬件一体化平台,深度集成全功能GPU计算、网络和存储,提供高可靠、高算力服务。通过该平台,用户可灵活管理多数据中心、多集群算力资源,集成多维度运维监控、告警和日志系统,帮助智算中心实现运维自动化。
KUAE ModelStudio模型服务:覆盖大模型预训练、微调和推理全流程,支持所有主流开源大模型。通过摩尔线程MUSIFY开发工具,可以轻松复用CUDA应用生态,内置的容器化解决方案,则可实现API一键部署。该平台意在提供大模型生命周期管理,通过简洁、易操作的交互界面,用户可按需组织工作流,大幅降低大模型的使用门槛。

▲夸娥(KUAE)智算中心解决方案支持端到端一体化交付
二、从“建起来”到“用起来”,夸娥突破4道难关
过去一年,我国千P级智算中心的智算基建布局集中爆发,根据工信部发布数据,截至2023年10月我国算力规模超300EFLOPS,智能算力占比高达35%。然而,国内的千卡智算中心仍处于发展初期,面临严峻挑战。
多位智算业内人士告诉智东西,我国智算中心建设既面临算力供应链问题,同时大规模内网互联、存储高速吞吐、模型优化服务、平台生态服务等技术因素也造成智算平台建设的技术瓶颈。
摩尔线程相关负责人谈道,集群建设是一个系统性复杂工程,从GPU显卡到服务器,最后把它组成集群,这里面包括了硬件的网络、存储、软件,再到大模型调度,是一个全栈式的工程,要真正把它做好,需要一个端到端的交钥匙方案。
从客户角度来讲,他们对千卡集群的算力利用率、稳定性、可扩展性和兼容性的需求最为突出。这也成为千卡集群建设要迈过的四道难关,摩尔线程为此做足了准备。
1、软硬协同,算力利用率提升超50%
算力利用率(MFU)是衡量智算中心能力的一个核心指标。即便是OpenAI在早期也面临MFU瓶颈,根据公开资料,其MFU在GPT-3训练阶段仅为21.3%,近79%的算力都被浪费了。
摩尔线程采用软硬协同设计、端到端的并行策略,使得综合调优下算力利用率(MFU)提升幅度超过50%。夸娥通过集群通讯库算法、网络拓扑、硬件规格合理设计和配置,优化集群匹配度;技术上,夸娥集群通讯算法网络拓扑综合利用了MTLink和PCIe,使得通讯性能提升一倍。
2、从芯片出厂开始,保证稳定可靠性
对于分布式训练而言,一张卡坏了,整个训练都会停掉。对于一个大规模集群来说,例如千卡甚至更大的集群,卡坏的概率会更高。所以,在做千卡集群或者更大规模集群时,它对整个集群的可靠性要求会更高。
摩尔线程从卡的出厂开始保证算力质量,做了很多严格的测试;开发了集群系统监控和诊断工具,帮助筛选和快速定位到有问题的卡和服务器,可以自动恢复和硬件替换;做了checkpoint加速,写的时间从10分钟降到秒级,读的速度从40分钟降到2分钟;判断训练异常,系统自动重新拉起。
3、提高可扩展性,线性加速比达91%
算力集群规模达到千卡,更是一个可扩展性的挑战。夸娥支持包括DeepSpeed、Megatron-DeepSpeed、Colossal-AI、FlagScale在内的业界主流分布式框架,并融合了多种并行算法策略,包括数据并行、张量并行、流水线并行和ZeRO,且针对高效通信计算并行和Flash Attention做了额外优化。
同时,夸娥结合了摩尔线程显卡硬件能力,以软硬一体的方式,做了系统级优化,包括从硬件、软件再到集群,外加云的全栈,不是单点突破,是一种全局综合方案,从而使得线性加速比达到91%。
4、零成本CUDA代码移植,兼容多个主流大模型
基于摩尔线程代码移植Musify工具,可快速将现有的主流迁移至MUSA,零成本完成CUDA代码自动移植,之后用户短时间内即可完成热点分析和针对性优化,大大缩短迁移优化的周期。此外,借助摩尔线程元计算统一系统架构MUSA,用户可以复用PyTorch开源社区的大量模型算子,降低开发成本。
与此同时,摩尔线程开源的MT Pytorch可以支持多种模型的推理,覆盖CV、NLP、语音等多个领域,能够运行典型的大模型分布式多卡推理,也可以支持单机多卡与多机多卡的分布式训练。利用数据并行、模型并行以及ZERO等分布式训练技术,MT PyTorch还可以完成简单基础模型以及典型Transformer结构的NLP语言模型的训练。

▲夸娥(KUAE)智算中心解决方案八大优势
总的来说,传统的计算模式在大模型时代面临着多重难点,只有长期投入并加强架构创新、软硬结合、场景结合、兼容协同等举措,才能够让智算集群完成从“建起来”到“用起来”的跨越。
三、国产大模型的超车时刻,“中国英伟达”交卷
打破英伟达对AI的垄断,国内外玩家都进入了一个“交卷”时刻。
在国外,我们看到亚马逊、微软、谷歌都已推出了面向大模型的AI定制芯片,对英伟达芯片进行部分替代,从而保证自家大模型持续可迭代和落地。
在国内,华为、摩尔线程、寒武纪、海光等头部AI芯片厂商,软硬件生态也已初具规模,技术架构自成一体,且已拥有集群能力和落地场景;同时多家AI芯片创企也在推动产品落地和量产,抢占大模型市场。
在备受关注的国产GPU领域,摩尔线程作为“中国英伟达”的主力选手,也已经打造了全栈AI方面的护城河。以全功能GPU为算力底座,摩尔线程夸娥提供从卡(MTT S4000)、服务器(MCCX D800)到千卡集群(K1、K2、K3)的完整智算产品组合,通过软硬一体化的服务,将成为大模型企业的最佳选择之一。
近日,摩尔线程正与无问芯穹联合推进基于夸娥千卡集群的“MT-infini-3B”合作大模型实训,目前性能已在同规模模型中跻身前列。无问芯穹联合创始人兼CEO夏立雪表示:“经无问芯穹Infini-AI平台实训与联合优化工作验证,摩尔线程夸娥千卡智算集群在精度、性能、易用性和算力利用率上均有优异表现,且在实训中实现了长时间稳定训练不中断,已可以为千亿参数级别大模型训练提供持续高效的高性能算力支持。之后我们会把这一合作模型在Infini-AI上开放给大家使用。”
随着今年“AI+”首次被写入两会工作报告,AI算力成为新质生产力的重要引擎,国产大模型进入关键的超车时刻。业内人士告诉智东西,今年大模型会出现一个拐点,同时也是国产AI芯片的分水岭,强者越强,弱者愈弱。
摩尔线程自2022年起就成立云计算团队,设定了建设千卡集群的大方向。在当时A100等算力紧张的背景下,摩尔线程作为在功能上唯一对标英伟达的国产GPU企业,在具备云的全栈能力后,构建基于全功能GPU的国产千卡智算集群,成为了国内赛道“第一批吃螃蟹的人”。随着大模型的爆发,摩尔线程夸娥智算中心解决方案已经完成从0到1的建设,有望成为国产大模型发展的重要引擎助力。
结语:国产大模型跨越时,千卡集群打造加速度
从ChatGPT到Sora,大模型之战已经愈演愈烈,国产大模型迫切需要加速追赶跨甚至超越,这催生了市场对更大规模、更高性能的计算资源的迫切需求,也推动计算中心的架构及运营模式进行更新换代。
千卡集群、万卡集群是满足AI算力需求的抓手,这一理念已逐渐深入人心。然而这种大规模智算集群的隐形壁垒越来越高,要求算力厂家在芯片、调优、通信及系统性开发和管理等多方面下功夫,从而真正跑出大模型产业发展的加速度。
,百模大战引爆“绍兴滨海新城 千卡集群竞赛”,“中国英伟达”交卷了相关:
多次弹窗暗示存在风险 手机下载App还需厂商同意? 多次弹窗暗示存在风险 烦琐操作才能下载安装 “下个App还得手机厂商同意才行?” 本报记者 韩丹东 “我自己的手机,想下个App还得手机厂商同意才行?”天津市某高校学生李女士从手机第三方渠道下载安装多款App时,都遇到不同程度地被手机系统拦截的情况,手机上不仅弹出安全风险提示和安全性确认,甚至需要李女士输入系统密码才能安装。 《法治日报》记者近日调查了解到,不少人遇到过和李女士一样下..
靠钻空子“变废为宝”真能行? 靠钻空子“变废为宝”真能行? 1.5亿余元特大制售假冒品牌洗衣机案成功告破 本报记者 刘洁 多台带有外包装的洗衣机被堆放在一起,纸箱上均清晰印有某知名电器公司品牌标志及洗衣机型号、颜色等,有些还贴有流转的物流单据;在仓库的另一角,成捆的产品合格证、说明书等被存放在几个箱子内,等待和未完成包装的洗衣机一起配套发出…… 这是执法记录仪留存的查处涉案窝点的画面。 自去年9月以来,..
柔性执法营造宽松营商环境 日前,四川宜宾一家从卖菜转行的采耳店,开业三天即被认定“无证诊疗”,合计被罚款22万元。执法机关如何确保“过罚相当,法理相容”、避免“小过重罚”,成为舆论热点。宜宾市翠屏区卫生健康局随后发布通报,称已撤回强制执行申请,并启动内部复查,将根据复查情况作出妥善处理。 法治是最好的营商环境。行政执法处在与市场主体打交道的第一线,市场主体对行政执法的感受最为真切。打造一流营商环境,必须规范行政执..
女子凌晨跳桥,路人下水营救结果两人均失踪?多方回应来源 | 潇湘晨报记者 | 王芊","type":"text"},{"data":{"duration":15,"bigPosterUrl":"https://x0.ifengimg.com/ucms/2024_17/1164537081A720230EE75AEC68A2A134A384ABE5_size95_w1080_h1920.jpg","attachmentType":"video","fileSize":"2390","guid":"7189778812672970752","attachmentId":"7189778812672970752","mobileUrl":"https://video19.ifeng.com/video09/2024/04/27/p7189778812672970752-102-081408.mp4","title..
昂达推出RX 6600 LE AEGIS显卡:双风扇和双热管、核心频率2495MHzIT之家 4 月 27 日消息,昂达近日推出一款 Radeon RX 6600 LE AEGIS 显卡,这款显卡相对于 RX6600 规格近乎相同(只有核心频率差别),不过官方没有公布该卡价格信息,该卡很有可能是 OEM 部件。IT之家注意到,这款显卡采用纯白色外观,使用 9cm 双风扇 + 双热管配置,拥有 1792 个流处理器、8GB GDDR6 显存、132W TBP,核心频率 2495MHz。此外,这款显卡使用 8pin x 1 供电,拥有 1 个 HDMI 2.1 接口和 3 个 DP 1.4a 接口。
消息称无底座谷歌Pixel平板起价3456元,比带底座版便宜34%原标题:消息称无底座谷歌Pixel平板起价446欧元,比带底座版便宜34%IT之家 4 月 27 日消息,谷歌计划推出不捆绑底座的 Pixel Tablet 平板,此外还会推出手写笔和键盘配件,近日该平板和配件的售价曝光。不带底座的 Pixel Tablet 平板电脑谷歌计划推出不带底座的 Pixel 平板电脑,有浅褐色(Hazel)和瓷白色(Porcelain)两种颜色,128GB 版售价为 446 欧元(IT之家备注:当前约 3470 元人民币)、256GB 版本售..
显卡又要涨价了!RTX 4060 Ti供应开始紧缺 英伟达要涨价10%快科技4月27日消息,英伟达计划上调游戏显卡的售价,预计涨幅约为10%。据悉,RTX 40系列的供货依旧紧缺,而主力型号的RTX 4060 Ti系列货源出现了较大的问题,使得供应量大幅度减少。虽然市场需求飙升,但是英伟达近期采取以不变应万变的策略,没有追加订单,使得RTX 4060 Ti系列的情况更为突出。几个主要的显卡品牌厂商,进入4月后的两周内,工厂供货端RTX 4060 Ti系列的供应量减量明显,每次每家的分货量只有最多50片左..
法国前总理的儿子:我和中国有很强的联结小伙潘雅德(Arthur de Villepin)是法国前总理多米尼克·德维尔潘的儿子(Dominique de Villepin)。他从小跟着外交官父亲周游列国,在美国、印度、法国和英国都长时间生活过,并且结识了赵无极、基弗、苏拉热、姜明姬等一众艺术大师。22岁那年,他选择在香港扎根,定居至今已超过10年。▲少年时期的潘雅德(右)和赵无极(左)4年前,他和父亲共同创立了画廊,开馆展便是 “亚洲最贵”艺术家赵无极的个展——赵无极和他们..
浙江宣传:不能什么事都压给基层近日,在重庆考察时,习近平总书记强调,为基层减负要明确权责,不能什么事都压给基层,基层该承担哪些工作,要把职责事项搞清楚。在中央层面整治形式主义为基层减负专项工作机制统筹协调推进下,近年来,从中央到各地各部门围绕精简文件会议、统筹规范督查检查考核、整治“指尖上的形式主义”、减轻村级组织负担、清理规范“一票否决”和签订责任状事项等,持续深化为基层减负工作,取得了阶段性成效。但在个别地方和部门,还存..
明明是与民争利,他们却诬民为恶霸内蒙开鲁县建华镇双胜村镇村两级干部阻挠农民春耕种地的事,这两天还在继续发酵。《纪副书记干过的岗位都与法有关,他却至今仍不懂法》一文,已经清楚地表明了我的态度。但有些脑残或者是心肠坏烂的人大肆攻击承包户,还说什么反转了。他们说反转,依据主要有两点:一个能以四块钱一亩的价格承包4650亩地的人,不是寻常农民,是恶霸,其中一定有资本运作;把草地更改成了耕地,破坏生态,这是违法的。真的反转了吗?如果认真看了..