
作者 | 程茜
编辑 | 心缘
智东西8月8日报道,今天下午,百川智能发布530亿参数规模的闭源大模型Baichuan-53B,这是百川智能发布的第三个大模型,主要服务B端行业,预计下个月将会开放API等相关组件。
百川智能4月10日成立后,6月15日发布了70亿参数规模开源模型Baichuan-7B,7月11日发布了130亿参数规模大模型Baichuan-13B,到今天,Baichuan-53B已经是其发布的第三个模型。百川智能创始人、CEO王小川透露,这次大模型的文科能力更好,比如在理解古诗、生成有个性化风格的文章等方面。
在大模型成果进展加快的同时,百川智能的商业化布局也已经开始。最近,搜狗原CMO洪涛在朋友圈官宣即将入职百川智能,负责商业化。王小川告诉智东西,洪涛回来代表了百川智能在商业化上的探索,一方面百川智能的大模型发布速度很快,另一方面也是其在商业化的考虑以及消费端应用的布局考量。
Baichuan-53B已经开放内测申请:https://chat.baichuan-ai.com/home
一、从响应、问答、筛选到结果优化,构建搜索增强系统
Baichuan-53B的预训练数据特点,包括全面的世界知识体系、系统的数据质量体系、多粒度的大规模聚类系统、细粒度自动化匹配算法。
搜索增强是解决模型时效性和幻觉的有效手段,因此,百川智能将搜索技术与大语言模型能力相结合,实现创新性的模型优化与改进。
搜索增强系统融合了指令意图理解、智能搜索和结果增强等关键组件,这一综合体系通过深入理解用户指令,精确驱动查询词的搜索,并结合大语言模型技术来优化模型结果生成的可靠性,基于此,百川智能实现了更精确、更智能的模型结果回答,减少了模型的幻觉。
其中,动态响应策略方面,百川智能将指令任务细化为16个独立类别,涵盖了用户指令的精准问答、逻辑推理、头脑风暴等各种场景,并针对每一个指令类别都进行了设计和优化。
智能化搜索词生成则是通过对问答样本进行精细化人工标注,捕捉和理解用户多元化的指令需求,大模型负责执行一系列关键任务,如时效性识别和搜索意图判别,从而准确解释用户的查询意图并精准响应。
为了达到高质量搜索结果筛选,百川智能构建了一个搜索结果相关性模型,对从搜索内容和知识库中获取的信息进行相关性评分。
在回答结果的搜索增强上,百川智能采用RLHF(人类反馈强化学习)技术,使得大模型能够参照搜索结果,针对用户请求生成高价值且具有实时性的回答。
除此以外,大模型还会通过对齐调整让模型同人类价值观对齐,生成令人满意的回复内容。
二、写作能力升级,搜索增强或成大模型差异化优势
王小川谈道,目前做大模型的主流创业公司中,百川智能是唯一一家做过超级应用的公司,包括搜索、输入法等,这些应用将语言用到极致,将当时最先进的语言变成模型从而构建超级应用。此外,冬奥会上的数字人就是搜狗提供的技术支持,可以看出,搜狗此前在AI方面有过诸多探索。
在现场,王小川演示了Baichuan-53B在起名字、生成大纲、写文案方面的能力。
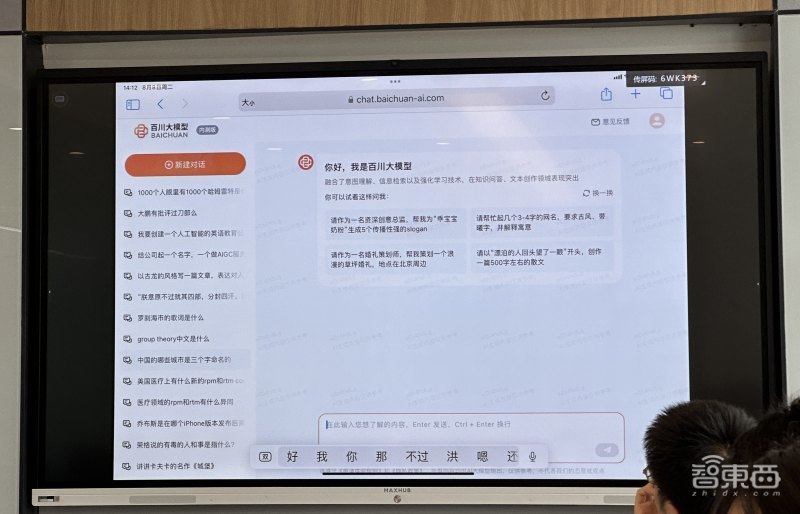
例如提问“如果要成立一个用大模型服务中小企业数字化升级的科技服务公司,可以起个什么公司名”。
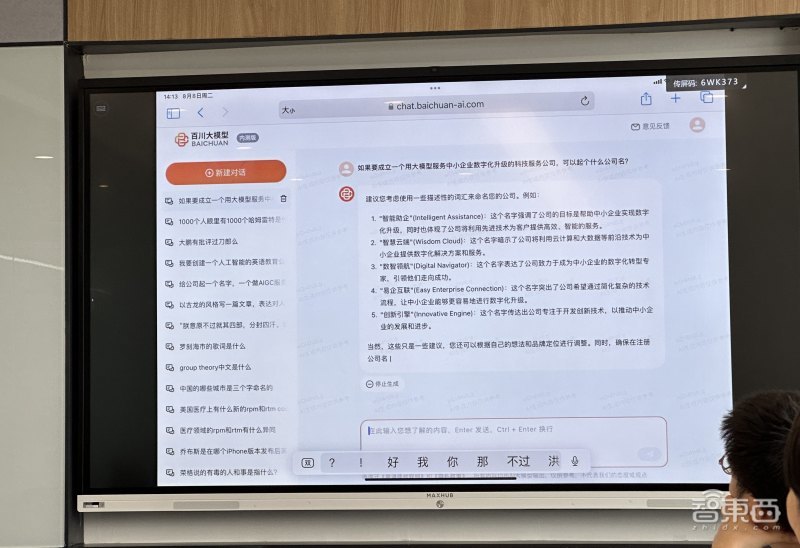
还有生成大纲的指令,如“帮我生成一份电动汽车品牌的调研汇报PPT大纲,并提供每页核心内容概要及配图建议”。
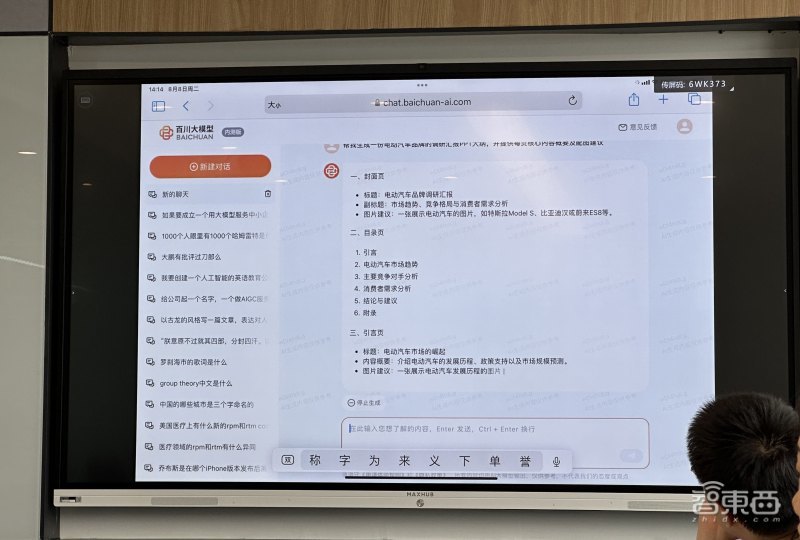
大模型的内容生成能力方面,现场演示的问题是“帮我以古龙的风格写个朋友圈,介绍我今天参加了篮球比赛的事情”。
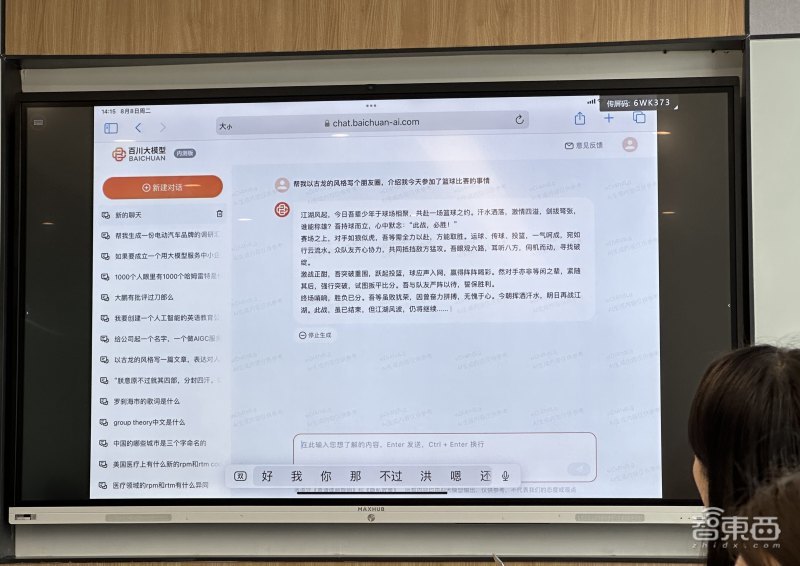
Baichuan-53B还可以写微信春节祝福语。
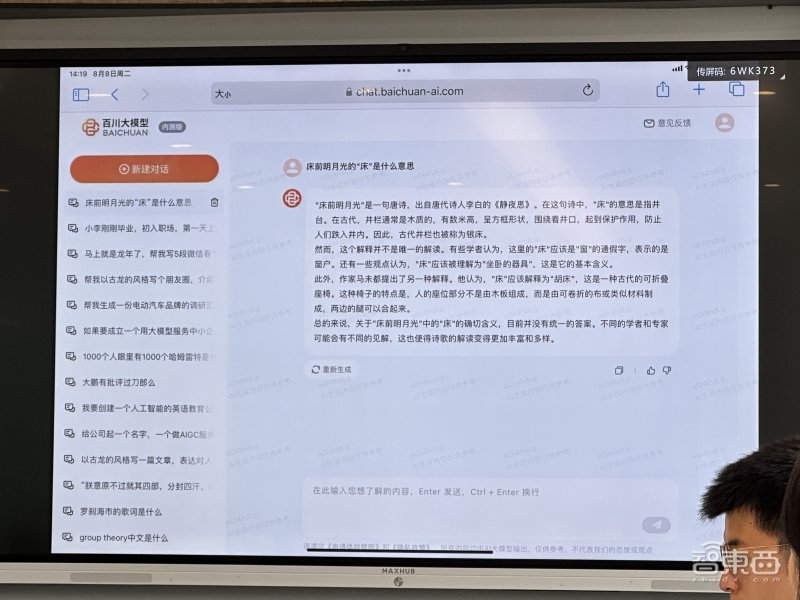
内容理解上,Baichuan-53B能解释“床前明月光的‘床’是什么意思”。
王小川提到,大模型出现之前,搜索引擎很难变成一个问答引擎。事实上,搜狗很早就将Transformer架构应用到搜索引擎中去,搜索本身也是一件强AI的事情。
在大模型发展尚处早期阶段,一些大模型的同质化现象出现,王小川认为,大模型的同质化是产业发展早期的正常阶段,而百川智能的搜索增强未来也会是其大模型发展的一大差异化优势。
三、互联网数据处理、模型训练、多元人才,百川智能三大杀手锏
成立至今,百川智能已经发布了三个模型,有150余家企业申请应用。百川智能技术联合创始人陈炜鹏告诉智东西,这背后有三大原因。
首先,做大模型的第一个环节是数据从哪来,中文互联网网页中的数据高达万亿、百亿量级,搜狗此前的数据积累,能让他们知道哪里有好的数据,并且将这些数据进行收集、处理、识别,在这一领域,百川智能目前的团队有很强的技术积累和方法论。
在英文数据方面也是如此,他补充道,搜狗在翻译领域的积累也有很多。
其次,模型本身的训练,模型的训练是一个相对复杂的系统,陈炜鹏谈道,这包括数据的获取、选择、配比、标注,数据准备好之后模型的训练框架,网络的运营效率如何组成框架,不同的算法如何组合,选用什么样的网络结构,统领这些如何评价这个事情,算法的选择等。百川智能此前的推出的70亿参数规模大模型在并行策略方面做的比较好,有技术积累。
最后,百川智能目前的技术团队有很多来自字节跳动、百度、华为的技术人才,也使得其技术能力更加多元。
综上,在技术和人才的共同加持下,百川智能在大模型的研发方面走的比较快。
王小川补充道,OpenAI的聊天机器人ChatGPT引爆了生成式AI的热潮,让资本、人才都认为这件事可行,因此一些技术在顶尖水平的人才都开始涌向大模型。
目前,火山引擎、阿里云、腾讯云都已经出现在了百川智能的合作伙伴名单里,火山引擎和百川智能的合作与Llama和微软合作的合作逻辑一致,王小川认为,之后云厂商都会开放和模型厂商的合作。
结语:开源、超级应用、比肩GPT缺一不可
王小川认为对国内大模型企业的评价应该包含三个维度,是否能拿出足够好的AGI从而能比肩GPT-3.5、GPT-4,是否有超级应用以及是否开源。
国外有OpenAI的GPT大模型能力、Meta发布的开源Llama大模型,国内目前大模型能力距GPT还有一定距离,百川智能优先对齐的就是开源大模型,能支持企业做私有化部署,其次要考虑的是应用问题,最后是比肩GPT-3.5、GPT-4。对于百川智能而言,王小川称,他们既有做对标GPT闭源大模型的能力,也能布局开源大模型。
相关:
海外网评:“去风险”的幌子藏不住美国的“黑手”资料图:芯片(图源:视觉中国)【编者按】近段时间,国际社会反对“去风险”的声浪渐高。德国《明镜周刊》日前以《如果“去风险”反而自乱阵脚》为题刊发评论指出,在对华政策中“去风险”本身就会造成不小的风险..
翻炒“太空竞赛”,美国太霸道(观象台)近日,美国国家航空航天局局长比尔·尼尔森到访阿根廷时,又将矛头对准中国。在新闻发布会上,他列举了中国在探月、探火等深空探索领域取得的成绩后声称,中美之间正在进行一场“太空竞赛”。这不是人们第一次从这..